Quickly delete all items in a DynamoDB table.
from : https://www.npmjs.com/package/dynamodb-empty
Quickly delete all items in a DynamoDB table.
from : https://www.npmjs.com/package/dynamodb-empty
AWS::ApiGateway::Method resource. Api:
Type: 'AWS::ApiGateway::RestApi'
Properties:
Name: MyProxyAPI
Resource:
Type: 'AWS::ApiGateway::Resource'
Properties:
ParentId: !GetAtt Api.RootResourceId
RestApiId: !Ref Api
PathPart: '{proxy+}'
Api.RootResourceId as its parent. The path part {proxy+} is a greedy match for any path. If you wanted to only match requests under e.g. /blog/*, you'd have to define two resources: BlogResource:
Type: 'AWS::ApiGateway::Resource'
Properties:
ParentId: !GetAtt Api.RootResourceId
RestApiId: !Ref Api
PathPart: 'blog'
Resource:
Type: 'AWS::ApiGateway::Resource'
Properties:
ParentId: !Ref BlogResource
RestApiId: !Ref Api
PathPart: '{proxy+}'
ANY method for each resource. RootMethod:
Type: 'AWS::ApiGateway::Method'
Properties:
HttpMethod: ANY
ResourceId: !GetAtt Api.RootResourceId
RestApiId: !Ref Api
AuthorizationType: NONE
Integration:
IntegrationHttpMethod: ANY
Type: HTTP_PROXY
Uri: http://my-imaginary-bucket.s3-website-eu-west-1.amazonaws.com/
PassthroughBehavior: WHEN_NO_MATCH
IntegrationResponses:
- StatusCode: 200
ProxyMethod:
Type: 'AWS::ApiGateway::Method'
Properties:
HttpMethod: ANY
ResourceId: !Ref Resource
RestApiId: !Ref Api
AuthorizationType: NONE
RequestParameters:
method.request.path.proxy: true
Integration:
CacheKeyParameters:
- 'method.request.path.proxy'
RequestParameters:
integration.request.path.proxy: 'method.request.path.proxy'
IntegrationHttpMethod: ANY
Type: HTTP_PROXY
Uri: http://my-imaginary-bucket.s3-website-eu-west-1.amazonaws.com/{proxy}
PassthroughBehavior: WHEN_NO_MATCH
IntegrationResponses:
- StatusCode: 200
{proxy+} is not enough to be able to use this in the target URL. You also need to specify RequestParameters to state that it is OK to use the proxy parameter from the path in the integration configuration.proxy parameter in your integration request path, by specifying Integration.RequestParameters. It is a map of parameters from the method request to parameters in the integration request.{proxy} to insert the proxied path in our integration uri.DependsOn to help Cloudformation figure out the order of things: Deployment:
DependsOn:
- RootMethod
- ProxyMethod
Type: 'AWS::ApiGateway::Deployment'
Properties:
RestApiId: !Ref Api
StageName: dev
AWSTemplateFormatVersion: 2010-09-09
Description: An API that proxies requests to another HTTP endpoint
Resources:
Api:
Type: 'AWS::ApiGateway::RestApi'
Properties:
Name: SomeProxyApi
Resource:
Type: 'AWS::ApiGateway::Resource'
Properties:
ParentId: !GetAtt Api.RootResourceId
RestApiId: !Ref Api
PathPart: '{proxy+}'
RootMethod:
Type: 'AWS::ApiGateway::Method'
Properties:
HttpMethod: ANY
ResourceId: !GetAtt Api.RootResourceId
RestApiId: !Ref Api
AuthorizationType: NONE
Integration:
IntegrationHttpMethod: ANY
Type: HTTP_PROXY
Uri: http://my-imaginary-bucket.s3-website-eu-west-1.amazonaws.com/
PassthroughBehavior: WHEN_NO_MATCH
IntegrationResponses:
- StatusCode: 200
ProxyMethod:
Type: 'AWS::ApiGateway::Method'
Properties:
HttpMethod: ANY
ResourceId: !Ref Resource
RestApiId: !Ref Api
AuthorizationType: NONE
RequestParameters:
method.request.path.proxy: true
Integration:
CacheKeyParameters:
- 'method.request.path.proxy'
RequestParameters:
integration.request.path.proxy: 'method.request.path.proxy'
IntegrationHttpMethod: ANY
Type: HTTP_PROXY
Uri: http://my-imaginary-bucket.s3-website-eu-west-1.amazonaws.com/{proxy}
PassthroughBehavior: WHEN_NO_MATCH
IntegrationResponses:
- StatusCode: 200
Deployment:
DependsOn:
- RootMethod
- ProxyMethod
Type: 'AWS::ApiGateway::Deployment'
Properties:
RestApiId: !Ref Api
StageName: !Ref StageName~/mykeypair.pem with the location and file name of your .pem file and replace ec2-###-##-##-###.compute-1.amazonaws.com with the master public DNS name of your cluster.
ssh -i ~/mykeypair.pem -N -L 8157:ec2-###-##-##-###.compute-1.amazonaws.com:8088 hadoop@ec2-###-##-##-###.compute-1.amazonaws.com
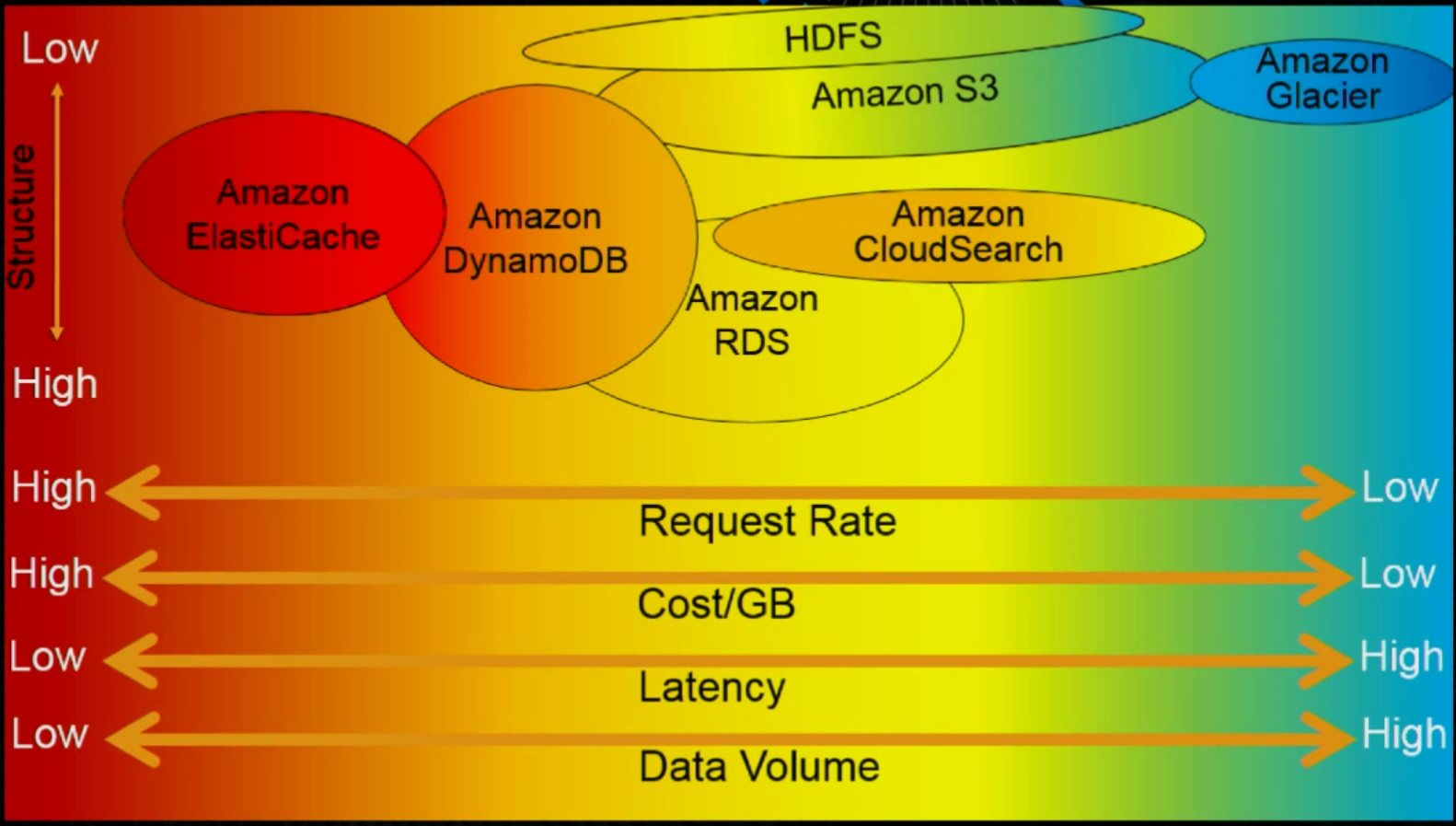
-L signifies the use of local port forwarding which allows you to specify a local port used to forward data to the identified remote port on the master node's local web server.http://localhost:8157/ in the address bar.CollectionDocumentPartition key:partition key,類似於 RDBMS 的 Unique Key.Partition key and sort key:partition key + sort key, 或者稱為 hash key + range keysort key 又叫 range attributehash key + range key 必須是唯一unique key + date range 這樣的組合。Global Secondary Indexes (GSI): 有自己的 Partition 和 RCU / WCULocal Secondary Indexes (LSI): 與 Table 共用 Partition 的 RCU / WCUScalar Types (純量): number, string, binary, Boolean, and null.Document Types: list and map.Set Types: multiple scalar values, 包含 string set, number set, and binary set.Eventually Consistent Reads (最終一致性, ECR): 每秒可以讀 2 次, 每次 4KB 大小,所以可以讀取最大為 8KiBStrongly Consistent Reads (強制一致性, SCR): 每秒可以讀 1 次, 每次 4KB 大小。1 2 3 4 5 6 7 8 | var params = { TableName: 'STRING_VALUE', /* required */ ConsistentRead: true || false, // ECR or SCR }; dynamodb.getItem(params, function(err, data) { if (err) console.log(err, err.stack); // an error occurred else console.log(data); // successful response }); |
Read Capacity Units (RCU)、Write Capacity Units (WCU).Read Capacity Units (RCU): 每次讀取單位為 4K4KB,那麼就會需要額外的 RCUWrite Capacity Units (WCU): 每次寫入單位為 1KB,超過大小就會額外消耗 WCUSecondary Indexes 會另外消耗 Capacity Units,有獨立的 RCU / WCU3000 RCU / 1000 WCU。建立 Table 時,如果指定 1000 RCU / 500 WCU,那麼需要的 Partition 計算公式如下:Total partitions for desired performance = (Desired RCU / 3000 RCU) + (Desired WCU / 1000 WCU)
( 1,000 / 3,000 ) + ( 500 / 1,000 ) = 0.8333 --> 1
( 1,000 / 3,000 ) + ( 1,000 / 1,000 ) = 1.333 --> 2
Partition Split 代表著拆分不同的區塊,儲存資料,每個 Partition 有其基本的讀寫能力與容量。一個 partition 可以儲存 10GiB 的資料,加上 RCU / WCU 的計算,所以以下兩個條件會發生 partition split:( 5000 / 3,000 ) + ( 2,000 / 1,000 ) = 3.6667 --> 4

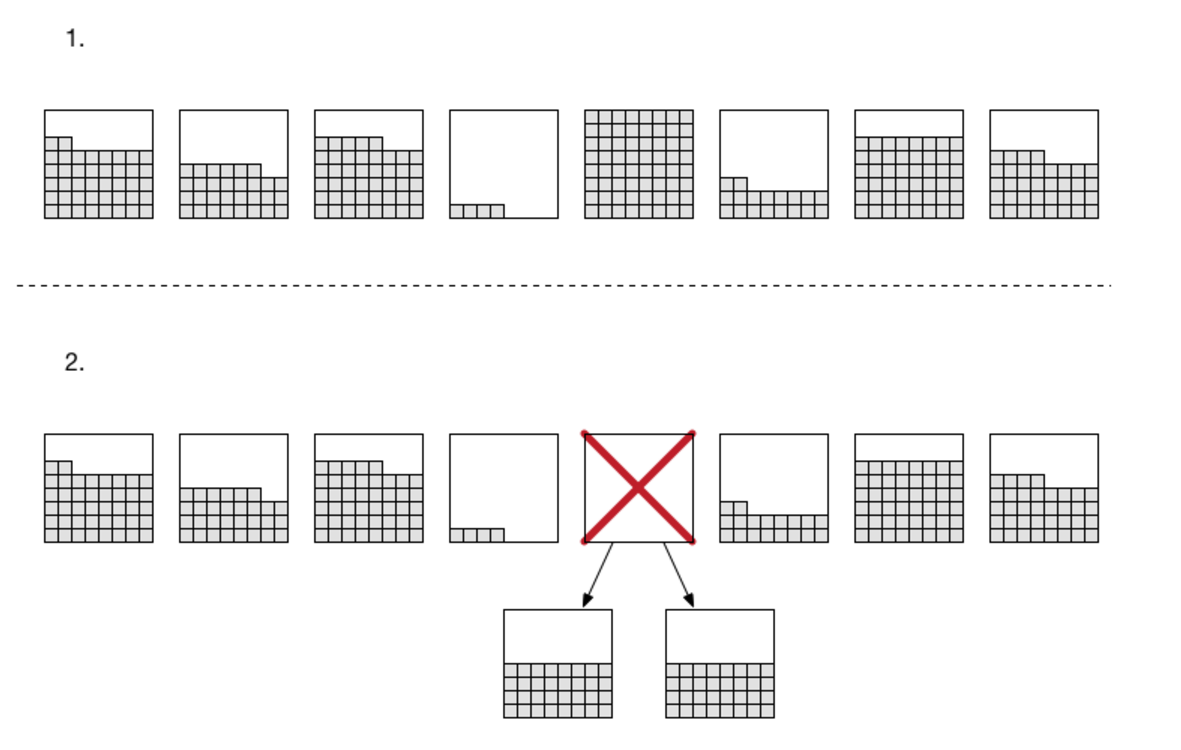
未來 burst 可能可以讓使用者自行設定。
In Memory 的方式,像是 ElasticCache,或者 DAX。Capacity Unit Sizes:40,000 RCU = 160MBytes, or 320MBytes
Connection 的概念,所以也不會有 Connection Pool 的問題。docker run -p 8000:8000 amazon/dynamodb-local1 2 | wget http://dynamodb-local.s3-website-us-west-2.amazonaws.com/dynamodb_local_latest.tar.gz java -Djava.library.path=./DynamoDBLocal_lib -jar DynamoDBLocal.jar -sharedDb |